Course Introduction
Professional certification
Google Professional Cloud Database Engineer
Design, manage, migrate, and operate Google Cloud databases for reliability, scale, and cost. This guide follows the official exam objectives with practical decision trees and checklists.
Want to pass faster?
Get practice tests + the latest deals/discount codes
Exam details (quick view)
Domains (by exam guide)
Service selection
Match SQL/NoSQL requirements to Cloud SQL, Spanner, Bigtable, and partner engines.
Connectivity & security
Networking, encryption, IAM, auditing, and session pooling choices.
Operate and tune
Monitoring, slow query analysis, indexing, and cost-performance optimization.
HA/DR and migration
RPO/RTO planning, replicas, PITR, and migration strategies.
Official Exam Objectives
Focus on design, management, migration, and deployment choices across Cloud SQL, AlloyDB, Spanner, Bigtable, Firestore, and BigQuery.
Exam Overview
Role: Database professional designing, managing, and troubleshooting Google Cloud databases.
Key skills: Translate business requirements into scalable, resilient, cost-effective solutions.
Focus areas: Design (32%), Management (25%), Migration (23%), Deployment (20%).
Section 1: Design (32%)
Choose the right database and HA strategy.
Capacity & usage planning
Sizing: high-memory for Redis/SQL buffers, high-CPU for compute-heavy workloads.
Storage: HDD vs SSD vs Balanced PD; know IOPS and throughput limits.
Scaling: vertical (Cloud SQL) vs horizontal (Spanner, Bigtable, Firestore).
Cost: CUDs for steady workloads; avoid Spot for primary databases.
HA & DR
Zonal: lowest availability.
Regional: standard HA with failover (Cloud SQL HA).
Multi-regional: survive regional failures (Spanner multi-region).
Maintenance: configure maintenance windows and denied periods.
Connectivity & security
Networking: PSC vs VPC peering; prefer private IPs.
Security: CMEK via KMS, audit logs, authorized networks.
Pooling: PgBouncer/ProxySQL for high connection counts.
Evaluating database solutions
Managed vs unmanaged: Cloud SQL/AlloyDB/ Spanner vs self-managed on GCE.
SQL vs NoSQL: SQL for ACID; Bigtable/ Firestore for scale; Memorystore for caching.
GenAI & vectors: pgvector or Vertex AI vector search for embeddings.
Section 2: Manage (25%)
Operate, secure, back up, and optimize.
Access management
IAM DB auth: use Google identities for Cloud SQL.
Roles: predefined roles with least privilege.
Monitoring & troubleshooting
Tools: Cloud Monitoring, Query Insights, Key Visualizer.
Symptoms: high CPU (indexes/queries), high RAM (buffer sizing), high I/O (disk limits).
Backup & recovery
RTO/RPO: define downtime and data loss tolerance.
PITR: Cloud SQL, AlloyDB, Spanner, Firestore.
Exports: gcloud/Console to GCS (SQL, CSV, Avro).
Optimization & automation
Scale up: increase CPU/RAM (Cloud SQL).
Scale out: read replicas (Cloud SQL), nodes (Bigtable/Spanner).
Automation: Cloud Scheduler, Cloud Functions, Terraform/Ansible.
Section 3: Migrate (23%)
Move data with minimal downtime.
Migration strategies
Lift & shift: move VM to Compute Engine.
Replatform: managed services (Cloud SQL).
Refactor: re-architect for Spanner or cloud-native.
Downtime: dump/restore vs CDC for near-zero downtime.
Database Migration Service
Use cases: MySQL, PostgreSQL, SQL Server to Cloud SQL/AlloyDB.
Features: snapshot + CDC, reverse replication fallback.
Other migration tools
Datastream: serverless CDC to BigQuery, Spanner, or GCS.
Native tools: pg_dump, mysqldump, bcp.
Bigtable: Dataflow templates for bulk imports.
Section 4: Deploy HA (20%)
Provision reliably with IaC.
Deployment concepts
IaC: Terraform for reproducible provisioning.
Safety: deletion protection, flags, parameter tuning.
Read replicas: cross-region replicas and promotion.
Testing HA/DR
Failover drills: manual failover in Cloud SQL.
App behavior: ensure connection strings handle DNS/IP changes.
Service Cheat Sheet
Cloud SQL
Managed MySQL/Postgres/SQL Server. Regional HA, read replicas. Best for < 30TB.
AlloyDB
Postgres-compatible, high-end analytics with columnar engine and disaggregated storage.
Cloud Spanner
Globally scalable SQL with strong consistency and 99.999% SLA.
Cloud Bigtable
Wide-column NoSQL for high throughput and low latency at scale.
Firestore
Document DB with real-time sync and offline support.
Memorystore
Redis/Memcached for caching and sub-ms latency.
BigQuery
Serverless data warehouse for analytics/ML, not OLTP.
Tips for the Exam
Read the case studies: watch for global availability, compliance, and latency constraints.
Keyword mapping: Global + strong consistency -> Spanner; IoT + time-series -> Bigtable; lift-and-shift -> Cloud SQL.
Managed vs serverless: Cloud SQL is managed, Firestore is serverless.
Flashcards
Cloud developer service choices and defaults
Question Text
Click to reveal answerAnswer Text
Database decision trees
Use these decision trees to pick the right database pattern quickly (service selection, HA, backups, scaling, and migration).
Data store choices
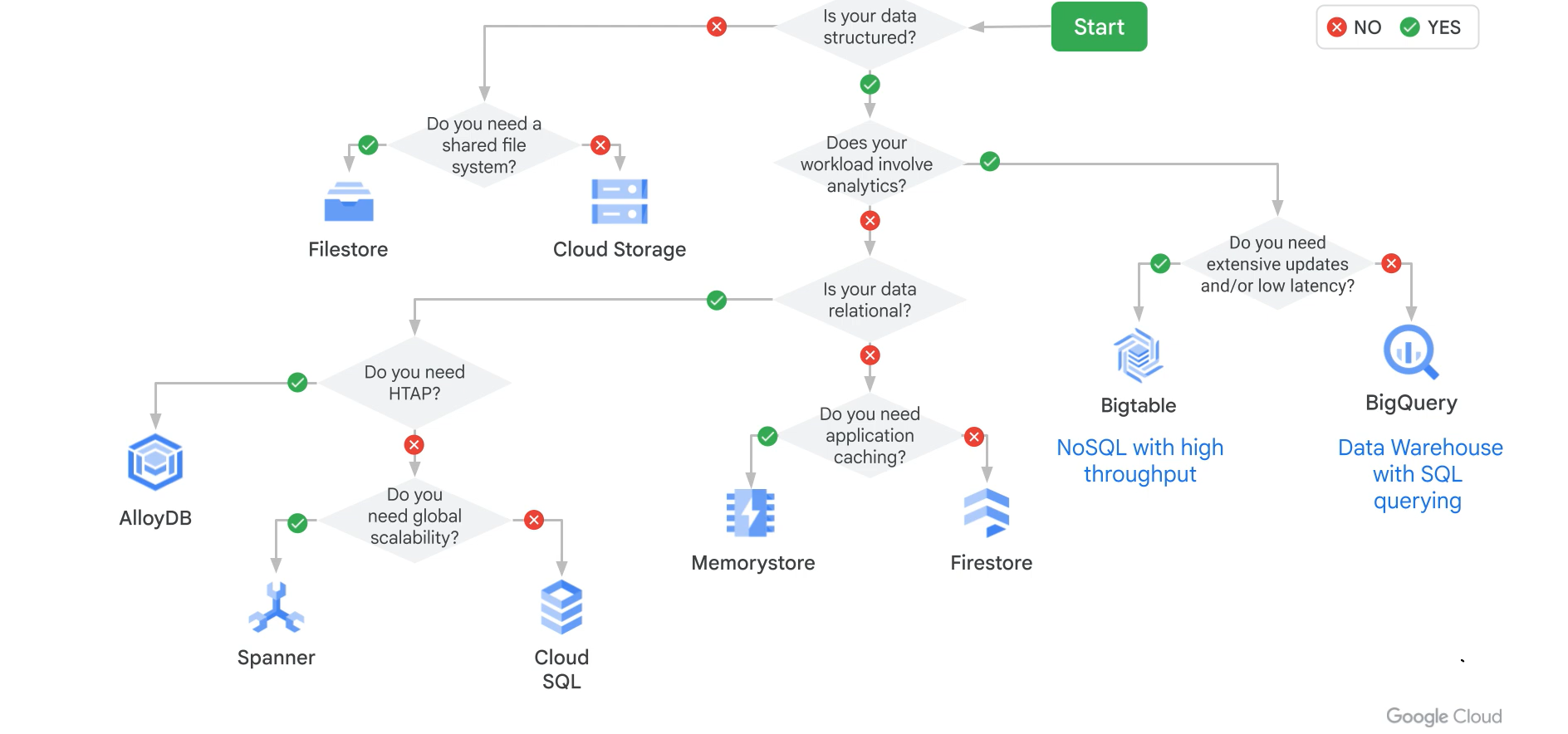
Click the diagram to zoom.
Decision tree 2 - Capacity and sizing
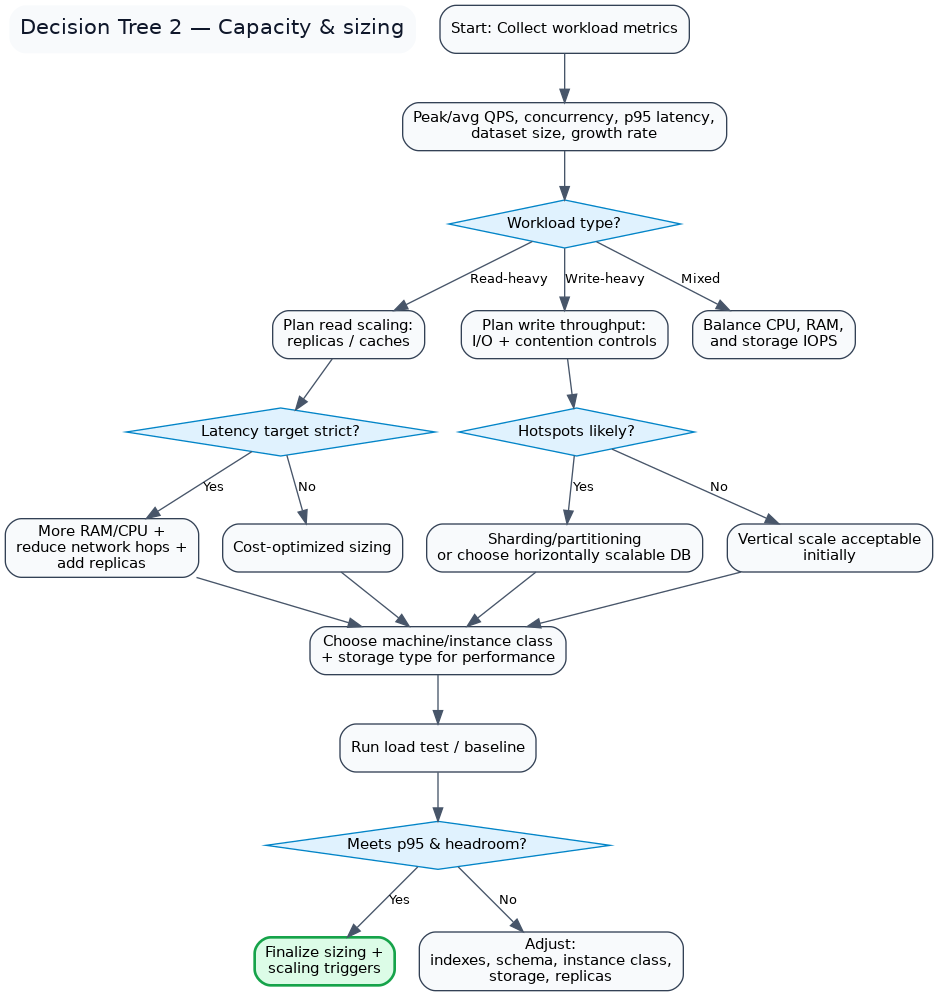
Click the diagram to zoom.